Benchmarking Agentgateway vs LiteLLM Part 2: Fixed Throughput
A fixed-throughput follow-up benchmark comparing agentgateway and LiteLLM at 3,000 QPS on latency, CPU, and memory using Fortio and a mock LLM backend.
In Part 1, I pushed both agentgateway and LiteLLM to their maximum throughput and compared latency, CPU, and memory usage. The downside of that benchmark was that each gateway was processing a very different workload. agentgateway handled roughly 10× the requests of LiteLLM so it wasn’t exactly an apples-to-apples comparison.
In this post, I use a fixed target throughput of 3,000 QPS for both gateways. This allows me to compare how efficiently each proxy handles the same traffic level.
Test setup
The benchmark uses a very simple architecture. A mock LLM server immediately returns a fixed response so the benchmark measures proxy overhead rather than model inference time.
Fortio generates traffic against each gateway at the configured rate.
fortio (bt) ──► litellm :4000 ───────┐
├──► mock-server (hyper-server) :8081
fortio (bt) ──► agentgateway :4001 ──┘I ran the benchmark with:
./scripts/run-benchmark.sh -q 3000 -d 30The benchmark uses:
- 32 concurrent connections
- Target throughput: 3,000 QPS
- 1 KB request payloads
- 30-second benchmark duration
Results
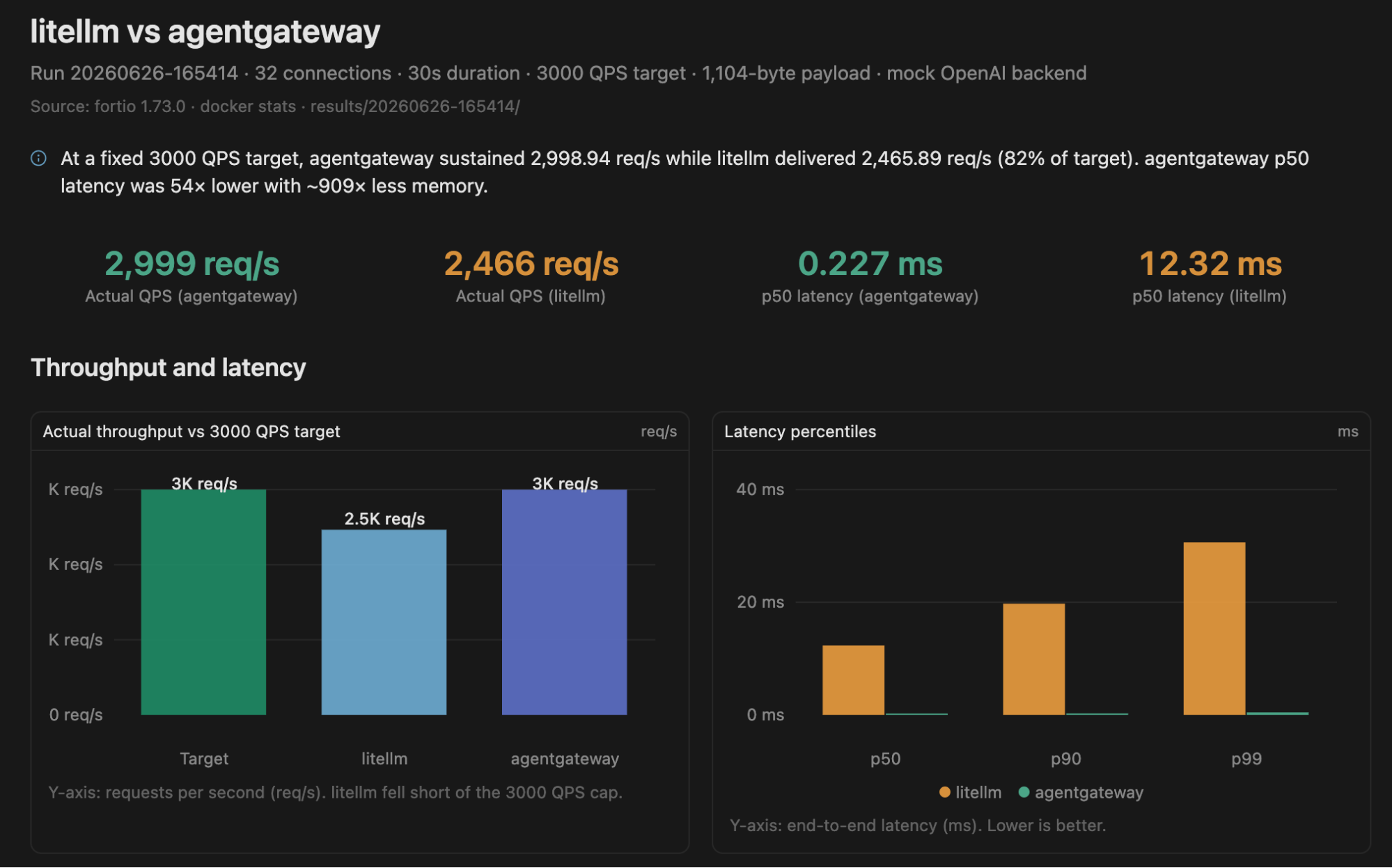
Throughput & Latency
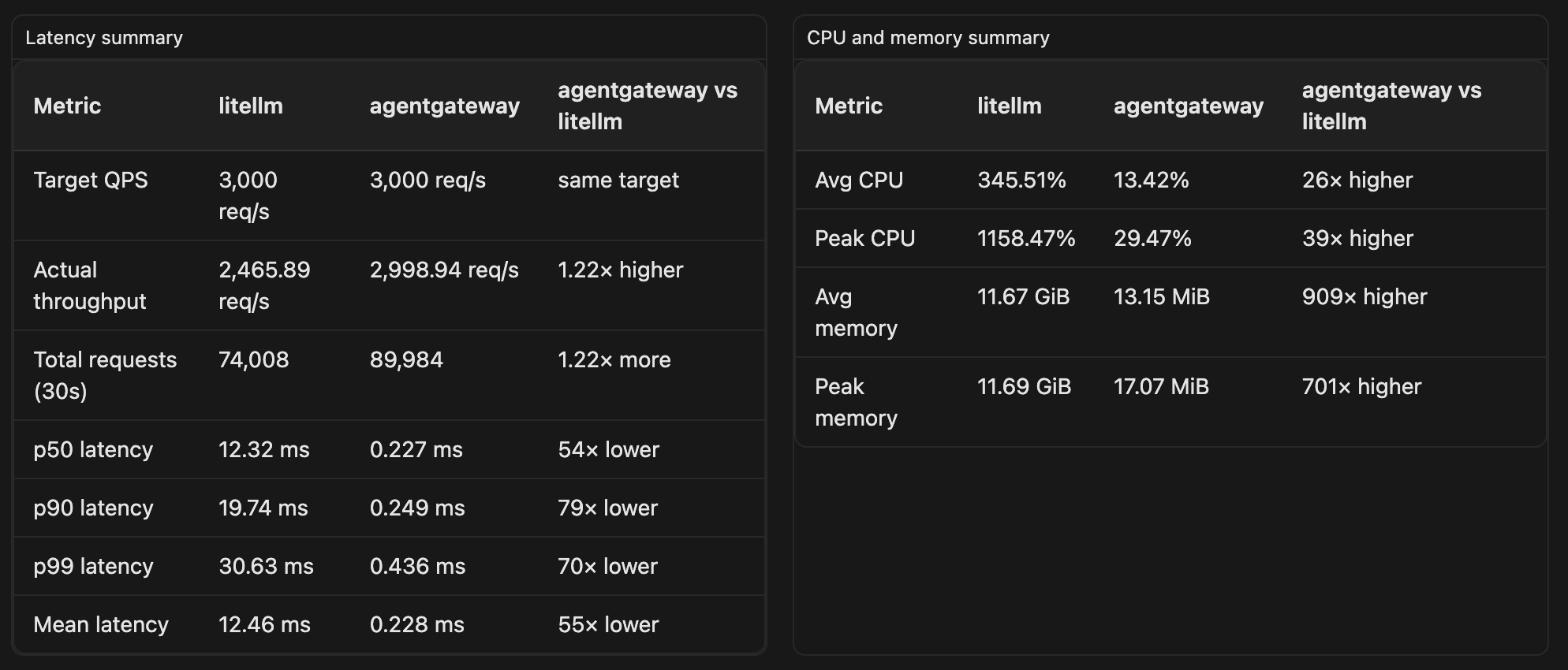
| Gateway | Actual Throughput | P50 | P90 | P99 |
|---|---|---|---|---|
| agentgateway | 2998.94 QPS | 0.227 ms | 0.249 ms | 0.436 ms |
| LiteLLM | 2465.89 QPS | 12.318 ms | 19.739 ms | 30.626 ms |
A few observations immediately stand out.
First, agentgateway sustained almost exactly the requested throughput of 3,000 QPS, processing 89,984 successful requests over the 30-second benchmark.
LiteLLM never reached the target rate. It averaged 2,466 QPS, about 18% below the requested throughput, completing 74,008 requests during the same period.
Latency was also dramatically different. agentgateway maintained a P99 latency below half a millisecond, while LiteLLM’s P99 exceeded 30 ms. Even median latency (P50) was over 50× lower with agentgateway.
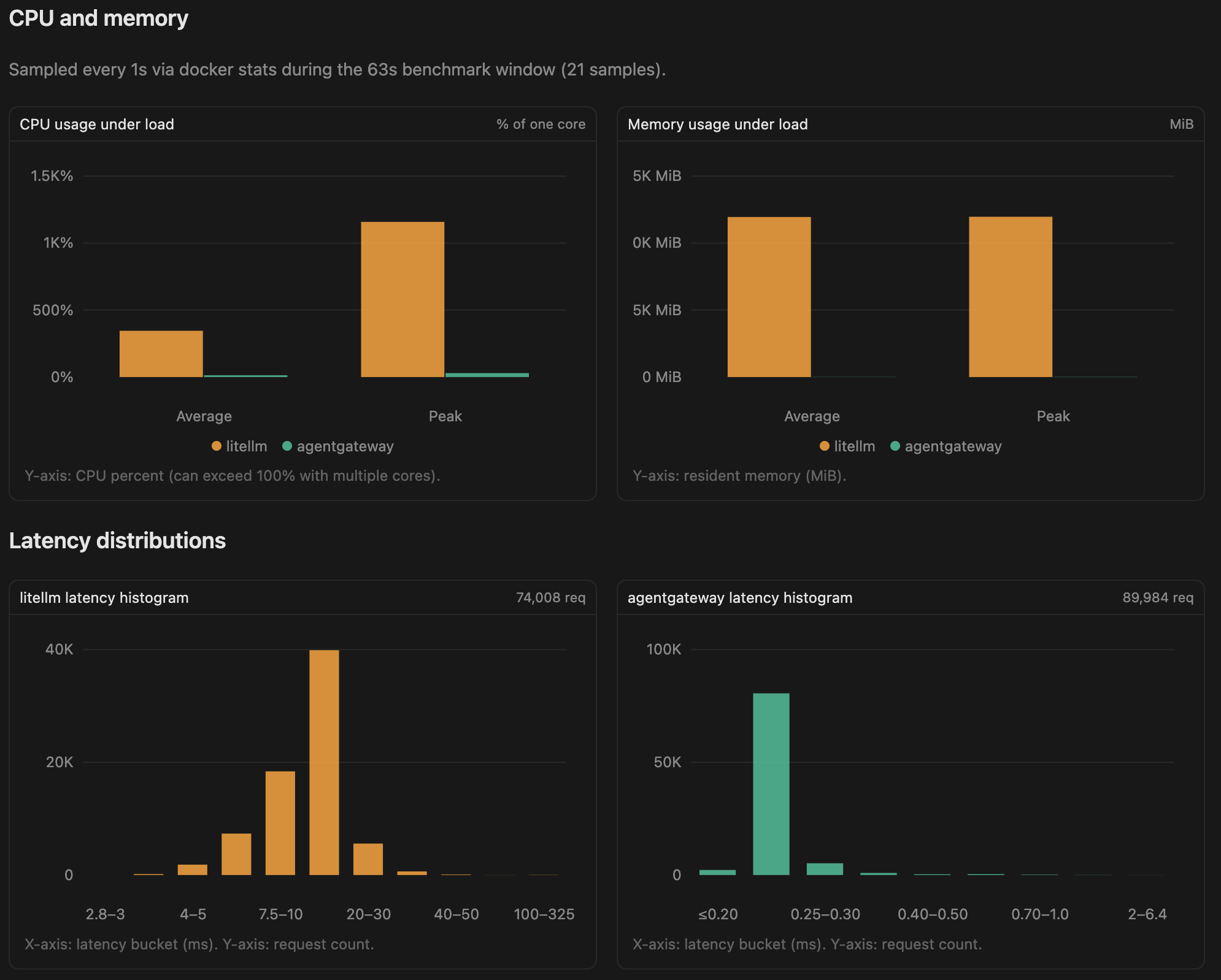
CPU & Memory
| Gateway | Avg CPU | Peak CPU | Avg Memory | Peak Memory |
|---|---|---|---|---|
| agentgateway | 13.4% | 29.5% | 13 MiB | 17 MiB |
| LiteLLM | 345.5% | 1158.5% | 11.67 GiB | 11.69 GiB |
The resource utilization is arguably even more interesting than the latency numbers.
At essentially the same request rate, agentgateway used only 13% average CPU, while LiteLLM averaged 345% CPU, roughly 26× higher.
Memory usage showed an even larger gap. agentgateway stayed around 13 MB throughout the test, whereas LiteLLM consumed nearly 12 GB of RAM.
This means agentgateway handled a higher request rate while using only a tiny fraction of the system resources.
Raw benchmark output
./scripts/run-benchmark.sh -q 3000 -d 30
==> Run ID: 20260626-165414
==> LiteLLM workers: 18
Running fortio to litellm at 3000 QPS for 30s and 32 connections...
qps: 2465.89qps p50: 12.318ms p90: 19.739ms p99: 30.626ms
Running fortio to agentgateway at 3000 QPS for 30s and 32 connections...
qps: 2998.94qps p50: 0.227ms p90: 0.249ms p99: 0.436ms
DEST,CLIENT,QPS,CONS,DUR,PAYLOAD,SUCCESS,THROUGHPUT,P50,P90,P99
litellm,fortio,3000,32,30,1104,74008,2465.89qps,12.318ms,19.739ms,30.626ms
agentgateway,fortio,3000,32,30,1104,89984,2998.94qps,0.227ms,0.249ms,0.436ms
CONTAINER,SAMPLES,AVG_CPU%,PEAK_CPU%,AVG_MEM,PEAK_MEM
perf-agentgateway,21,13.42%,29.47%,13.15MiB,17.07MiB
perf-litellm,21,345.51%,1158.47%,11.67GiB,11.69GiB
perf-mock-server,21,6.23%,8.59%,3.06MiB,3.17MiBVisualized results
I asked Cursor to turn the raw benchmark data into a few charts:
Takeaways
Compared with the “maximum throughput” benchmark in Part 1, this test removes one important variable by targeting the same request rate for both gateways.
Even under this controlled workload:
- agentgateway sustained the full 3,000 QPS target, while LiteLLM averaged 2,466 QPS.
- P99 latency was under 0.5 ms for agentgateway versus over 30 ms for LiteLLM.
- agentgateway used approximately 26× less CPU on average.
- Memory usage remained around 13 MB, compared to nearly 12 GB for LiteLLM.
Like the first benchmark, this test intentionally isolates proxy overhead by using a mock backend. It does not evaluate model inference latency or compare gateway features. If your application spends hundreds of milliseconds waiting for an LLM response, proxy latency becomes less significant.
However, if you’re building high-throughput AI infrastructure, serving many concurrent requests, or simply want a lightweight local gateway to manage all of your LLM providers, proxy efficiency matters. In this benchmark, agentgateway consistently delivered lower latency while using substantially fewer CPU and memory resources.
The complete benchmark scripts and raw results are available in the GitHub repository if you’d like to reproduce the numbers yourself.